![[Home]](/~megera/oddmuse/zen3.gif)
2009-07-21
HadoopDB
Very interesting announcement HadoopDB !
Quote: "It's an open source stack that includes PostgreSQL, Hadoop, and Hive, along with some glue between PostgreSQL and Hadoop, a catalog, a data loader, and an interface that accepts queries in MapReduce or SQL and generates query plans that are processed partly in Hadoop and partly in different PostgreSQL instances spread across many nodes in a shared-nothing cluster of machines. In essence it is a hybrid of MapReduce and parallel DBMS technologies. But unlike Aster Data, Greenplum, Pig, and Hive, it is not a hybrid simply at the language/interface level. It is a hybrid at a deeper, systems implementation level. Also unlike Aster Data and Greenplum, it is free and open source."
2009-07-13
Annapurna 2
Update: Selected Nepal pictures available on Flickr
Annapurna 2 (click to see it larger). Ufraw+Gimp(resize+inverse diffusion).


2009-06-21
tail /etc/modprobe.d/blacklist ############ I dont' want usb audio !!! blacklist snd_usb_audio blacklist ipaq blacklist usbserial blacklist snd-pcm-oss
The last line was crucial to have sound in flash plugin for firefox and other linux programs !
2009-05-06
Return to Moscow from Nepal
13 hours flight from Kathmandu to Moscow by Qatar, no problem, except usual one with my legs :)
Below is a quick summary of my visit:
- Nepal is a nice country with big openness and honest people
- Annapurna Circuit - 210 km with scenic views, easy trek for relaxed people with guide and porters and good test if you're 50-ty and is going alone. Also, "On the Road" is a good book to read before.
- I did full trek from Besisahar ( April 11) to Nayapul ( April 30) plus Tilicho lake trek, upper way through Ghyaru-Ngawal and short trek to Dhaulagiri lakes from Larjung - about 300 km with 16 kg backpack (Golite Pinnacle, thanks to my groupmate from NASA), ~ 3 kg camera + accessories, plus about obligatory water (1 litre) and hot tea ( 1 litre). I didn't come to the ABC, since I was not able to find companion to do it for 4 days and it would be wrongly to go alone. Actually, we ( me, Simon from Bristol and Jack from Uta) discussed that possibility, but Simon was really tired and Jack had a bit different timings. I met Jack in Kathmandu and he said he did ABC only for 5 days and it was really difficult. I still think I would be able to do ABC for 4 days if I would find my russian friends Tatopani or Ghorepani and share 5 or so kg of my stuff ( it happens that they just finished trek in Tatopani and went to Beni by bus, shame :)
- Kathmandu ( 3 nights for getting permits, byuing equipment and looking around) - Besisahar by jeep (start) - Ngadi - Jagat - Bagarchap - Chame - Ghyaru - Manang (2 nights: Milarepa Cave, Tilicho run by left side) - Tilicho Base Camp - Tilicho Peak Lodge - Thorung Phedi - Muktinath - Kagbeni - Marpha - Larjung - Tatopani - Ghorepani - Nayapul (finish) - Pokhara by taxi - Kathmandu by bus ( 4 nights relaxing, browsing and shopping for gifts)
- Difficult parts (by different reasons) were : 400 m up to Ghyaru, Tilicho 1000m up, 1600 m down from Thorung pass to Muktinath after 1000 m up from Phedi to the pass, 1600 m up to Ghorepani (one day) and so galloping down next day (my knees were good, but was about to say "stop").
- Nice parts : Ghyaru - scenic view on Annapurna 2 (me and va109.liverjournal.com were just shocked by so close view and wild village we haven't seen before. Hmm, the room was also interesting), Tilicho - in spite of snowing there were interesting plays of light and views to Gangapurna and Tilicho peak when coming back, Muktinath+Kagbeni were fascinating (much more to say), Manang for their bakery, Marpha for it mild hospitality, Larjung for unforgettable relax after lurking for Dhaulagiri lakes with Simon, Tatopani for the beautiful relax in hot springs after long walk from Larjung (with Simon and Jack), Ghorepani - real hot shower after whole day of exhausting climbing (usually it takes 2 days)
- I met a lot of interesting people. Actually, only some specific kinds of people came to Nepal.
My next plan is to go in October for combined trek "Gokyo lakes + Everest Base Camp".
Pictures will be available after processing them from RAW. I have quite dense schedule for may and june, so don't expect soon, sorry.
Update: Several random images (Annapurna, Nikon D90, Nikkor 18-200)



2009-04-03
Red-Black Tree experiments
Red-Black tree will eventually replaces BTree in GIN code. BTree suffers from the curse of sorted data (tree became very nonbalanced, so tree degenerates to the list with O(N^2) processing time, see thread http://archives.postgresql.org/pgsql-performance/2009-03/msg00340.php) ). Create index for such data will be amazingly slow, so we decided to replace BTree in GIN by RB-tree, which is self-balanced binary tree, to defense from such bad behaviour. This will affect bulk insert, i.e. create index and pending list cleanup. Tom Lane recently submitted quick defence against such behaviour into 8.3 and HEAD.
Teodor did quick test of rb-tree:
SEQ: SELECT array_to_string(ARRAY(select '' || a || '.' || b from
generate_series(1,50) b), ' ')::tsvector AS i INTO foo FROM
generate_series(1,100000) a;
RND: SELECT array_to_string(ARRAY(select '' || random() from
generate_series(1,50) b), ' ')::tsvector AS i INTO foo FROM
generate_series(1,100000) a;
Time of create index command in seconds.
SEQ RND
HEAD 140.131 119.160
rbtree 115.567 12.393
Update: Second query actually produces identical records, so it illustrates degenerated case of very unbalanced data, where rbtree has a huge advantage (as it follows from the result).
Test with random arrays with maxlen=1000, total 100,000 rows and 500,000 unique values shows rbtree slightly slower than HEAD code (with defense).
RND (fu=on) RND (fu=off) HEAD (s) 175.762 180.061 rbtree 185.567 184.012
Repeat test with 100,000 identical records varying array length (len).
select ARRAY(select generate_series(1,len)) as a50 into arr50 from generate_series(1,100000) b;
len=3 len=30 len=50 RND (teodor's)
HEAD (ms) 835.792 3673.383 7498.342 9990.729
Mark 324.251 2163.786 3306.074 4725.556
rbtree 797.571 3771.747 7304.004 13440.959
Mark 299.090 2828.424 3984.456 3514.972
Update: I added results from Mark Cave-Ayland
Results from experiment with real data (electronic papers archive) isn't very optimistic about rb-tree, but show almost the same performance as for BTree (plus recent defense by Tom Lane).
Btree:
arxiv=# create index gin_x_idx on papers using gin(fts);
CREATE INDEX
Time: 81714.308 ms
arxiv=# select pg_total_relation_size('gin_x_idx');
pg_total_relation_size
------------------------
319225856
RB-tree
arxiv=# create index gin_x_idx on papers using gin(fts);
CREATE INDEX
Time: 86312.517 ms
arxiv=# select pg_total_relation_size('gin_x_idx');
pg_total_relation_size
------------------------
319799296
(1 row)
2009-03-25
hstore rulez !
It's pleasantly to see new activity around our contribution Hstore. See http://archives.postgresql.org/pgsql-hackers/2009-03/msg00940.php for details.
I think, while all these new functions and operators are nice to have, but the most serious feature is to improve hstore indexing (make index more selective), which I and Teodor was planning for the long time.
2009-03-24
GIN fastupdate committed !
Tom Lane just committed GIN fastupdate patch to the CVS HEAD. We spent about 30 versions of the patch since last PGCon 2008 ! The basic idea was described in commit log:
Log Message: ----------- Implement "fastupdate" support for GIN indexes, in which we try to accumulate multiple index entries in a holding area before adding them to the main index structure. This helps because bulk insert is (usually) significantly faster than retail insert for GIN. This patch also removes GIN support for amgettuple-style index scans. The API defined for amgettuple is difficult to support with fastupdate, and the previously committed partial-match feature didn't really work with it either. We might eventually figure a way to put back amgettuple support, but it won't happen for 8.4. catversion bumped because of change in GIN's pg_am entry, and because the format of GIN indexes changed on-disk (there's a metapage now, and possibly a pending list). Teodor Sigaev
Tom removed pending list cleanup during vacuum analyze command, which now occurs only during "auto-ANALYZE".
Also, GIN got defense from degradation when the input data are sorted or so, which case the tree unbalanced and the insertion speed become O(N^2). We hope in future release to implement rebalancing tree algorithm, Teodor's idea
> Yes, this is probably the same issue I bumped into a while ago: > > http://archives.postgresql.org/message-id/49350A13.3020105@enterprisedb.co > m Exactly. I'm working on red-black tree to solve that, but for next release because of feature freeze.I'd like to implement some generic tree because it will be useful in several parts of postgres: - GIN - Bentley-Ottomann algorithm for intersection and containment of polygons. Currently, intersection of polygons checks only bounding boxes, contains algorithm doesn't work correctly for complex (and even just concave) polygons. Now I did implementation of red-black tree although it's not well tested.
2009-03-23
Confuse with text search
One expect true here, but result is dissapointing false
postgres=# select to_tsquery('ob_1','inferences') @@
to_tsvector('ob_1','inference');
?column?
----------
f
(1 row)
We can use ts_debug function to understand the problem
postgres=# select * from ts_debug('ob_1','inferences');
alias | description | token | dictionaries | dictionary | lexemes
-----------+-----------------+------------+-----------------------------+-------------+------------
asciiword | Word, all ASCII | inferences | {french_ispell,french_stem} | french_stem | {inferent}
(1 row)
postgres=# select * from ts_debug('ob_1','inference');
alias | description | token | dictionaries | dictionary | lexemes
-----------+-----------------+-----------+-----------------------------+---------------+-------------
asciiword | Word, all ASCII | inference | {french_ispell,french_stem} | french_ispell | {inference}
(1 row)
Now, we see that real problem is that french_ispell doesn't recognized plural form of word 'inference' (ispell and stemmer stem word 'inferences' differently, which is ok ).
What to do ? The best way is to teach ispell dictionary, the easiest way is to use synonym dictionary and put it first in the stack of dictionaries:
inferences inference
And don't forget to reindex !
btw, another way is to use ts_rewrite, so you don't need to reindex.
2009-03-22
astronet.ru selected stats
megera@mira:~/app/astronet/logs $>wc astronet-visitors.log 318221086 954662552 12975217257 astronet-visitors.log
318,221,086 total accesses to the astronet ( 2001-2009), without accesses to images.astronet.ru, which should be way more, since astronomical images are quite popular.
cat astronet-visitors.log| awk '{print $1}'|LC_CTYPE=C sort| LC_CTYPE=C uniq -c| LC_CTYPE=C wc
4784728 9569370 105249049
4,784,728 unique visitors
Below is the Number of visitors for top-6 russian astrosites. Visitors are in percents of total (whole world) visitors ! More information available
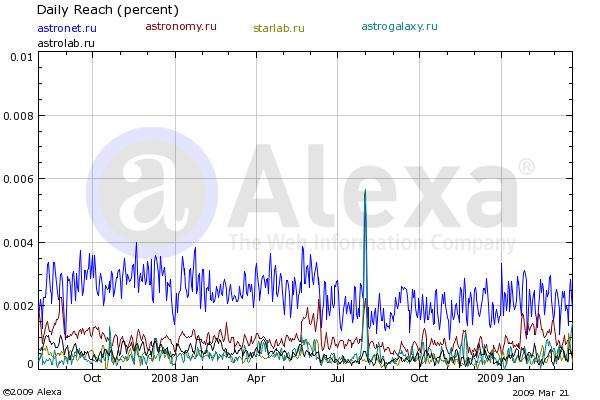
Current astronet statistics

2009-03-21
Google does semantic search
Search google for Apparent magnitude of jupiter and you'll get
Jupiter — Apparent Magnitude: 1.6 to -2.94 According to http://www.answers.com/topic/jupiter - More sources »
It means, google understands semantic tagging, see Wikipedia page about Jupiter. Look on info box on the right.
Better example: supernova type of sn 1987a
SN 1987A — Supernova Type: Type II-P (Unusual) According to http://en.wikipedia.org/wiki/SN_1987A
Update: New semantic search just started- WolframAlpha

